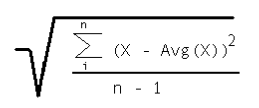|
|
The features on this page require a GENESIS64 Advanced license and are not available with GENESIS64 Basic SCADA . |
|
|
The features on this page require a GENESIS64 Advanced license and are not available with GENESIS64 Basic SCADA . |
Starting from v10.91, Hyper Reader is a part of standard Hyper Historian installation. Prior to this version, it was distributed as a standalone set of assemblies (available for 10.86, 10.87 versions). Hyper Reader assemblies are located in ‘ICONICS\GENESIS64\Components\’ folder.
The following table describes Hyper Reader assemblies:
|
Assembly name |
Description |
|
HyperReaderPlugins.dll |
Input and output plugins (Hyper Historian reader and SQL server writer) |
|
HyperReaderCommon.dll |
Common classes and definitions |
|
HyperReaderCore.dll |
Data transfer mechanism, connects input and output plugins |
|
HyperReaderCoreHost.exe |
Command line host |
|
HyperReaderCoreHost.exe.config |
Application’s configuration settings |
Hyper Reader is a command line tool, which needs relatively huge set of configuration settings to complete data transfer task correctly. It needs to know input data variable names, connection string to target DB, output table name, etc. To keep execution of this tool simple, XML configuration file is used. Some of the settings in configuration file can be overridden by command line parameters.
To reduce memory and CPU consumption, especially for large data transfers, Hyper Reader talks to Hyper Historian logger directly over NamedPipes protocol. This enforces one limitation - Hyper Reader has to run on the same box as Hyper Historian Logger. Target database doesn’t have such limitation. Recovery, in case of any error, is done on both sides – between Hyper Historian and Hyper Reader as well as between Hyper Reader and target database.
Hyper Reader processing can be interrupted at any time by Ctrl+C command.
Information messages about overall data transfer process can be traced out to TraceWorX (default option) or Windows Application Event Log. This setting is available in HyperReaderCoreHost.exe.config file, section appSettings, and key LoggerType. Value can be either WindowsEvents or TraceWorX. To see messages in the TraceWorX log, tracing for Hyper Reader module has to be enabled. Easiest way to enable it is to open up Trace Configuration and enable traces for module “Hyper Reader”. However this item may not be available for patched systems (prior version 10.92) thus manual modifications of the TraceWorX files are needed.
To do it, modify ‘IcoTraceSettings.xml’ file in ‘ICONICS\GENESIS64\Components’ folder and add the following line into the ‘categories’ section:
<category TraceCategoryName="HyperReaderCoreHost.exe" TraceCategoryDisplayName="Hyper Reader" />
Command line parameters uses standard command line parameters pattern, where each parameter start with – (dash) character and is followed by parameter name (see table below). Parameter value is then separated by one or more space characters. When a parameter value contains spaces then it has to be wrapped by double quote characters, e.g. “Value with spaces”. Command line command may contain any number of parameters in arbitrary order.
|
Parameter |
Mandatory |
Value |
|
-s |
Yes |
A file path to the configuration file. |
|
-ti |
No |
Input database table name, a table where point information is stored. Overrides SqlQuery configuration parameter in HyperHistorianInputPluginConfiguration section. |
|
-st |
No |
Batch start time, when it isn’t specified then Now() – 1 hour is used. |
|
-et |
No |
Batch end time, when it isn’t specified then Now() is used. |
|
-to |
No |
Output database table name, a table where historical values are stored. Overrides TableName configuration parameter stored in SqlServerOutputPluginConfiguration section. |
|
-o |
No |
Output table creation option – can be one of the following values: - Create - DropAndCreate - Append Overrides configuration parameter. |
Configuration file is a XML codded file derived to two basic sections – input (Hyper Historian) configuration and output (SQL Server) configuration.
This section contains all data retrieval settings (input of the Hyper Reader).
|
Value Name |
Default Value |
Description |
|
ConcurrencyLevel |
100 |
Maximum number of the input tags processed in parallel. This setting have direct influence to amount of CPU and memory used by Hyper Historian. Higher numbers may temporarily increase memory consumption and speed up overall merge process. But merge speed can be also limited by the speed of target SQL server. |
|
MaxValuesPerNode |
5000 |
Maximum number of values that can be returned by Hyper Historian in a single one call. Maximum number is 10 000. When this number is too high it may cause communication difficulties (may exceed communication buffer size) and slow down overall merge performance. |
|
ConnectionTimeout |
30 |
In seconds, the time between communication retries (communication between reader and HH logger) |
|
RetryDelay |
15 |
In seconds, specifies for how long the reader waits between read retries. |
|
RetryCount |
5 |
How many times in a row Hyper Reader tries to read values from a failing source tag. When this number is reached and data can’t be read then reader stops reading values from this tag. |
|
ReturnBounds |
false |
When true then boundary values are written to the output table. Boundary values are closest values before and after specified time domain. |
The following part describes data tag sources. There are two subsections available, both are optional, however at least one of them has to be specified.
Allows to specify list of data tag names to be read by Hyper Reader. This list can be combined with a list of data tags specified in the input database table specified in <SourceTagsLink/> subsection. The following is a single data tag entry:
<SourceTag Name="hh:\Configuration\Signals:RampFast" />
In this section, access to the input database table (a table containing list of data tag parameters to be read by Hyper Reader) can be specified. Input table may have multiple columns, where at least one column is textual and contains data tag names (either partial or fully qualified) codded in FwxClient friendly syntax. Beginning part of the tag name can be omitted and replaced by configured prefix stored as <PointNamePrefix/> value. An optional column with Id can be used. This id is used in the output table to identify each exported value. If this id is not specified then Hyper Reader uses tag name instead. Since tag name can be quite long text also output table may become quite huge due to tag names stored with each exported value.
The following table describes values available in this section:
|
Value Name |
Default Value |
Description |
|
ConnectionString |
Empty string |
A connection string to the SQL server database containing input data. |
|
SqlQuery |
Empty string |
A table name, view name or SELECT SQL query can be specified. Returned dataset have to contain data tag information (tag name, optionally tag id). This value can be overridden by command line argument –ti. |
|
TagNameColumnIndex |
-1 |
Zero based index to specify position of a column containing data tag names. This column has to be textual and has to contain either partial or fully qualified tag names codded in FwxClient syntax. |
|
TagIdColumnIndex |
-1 |
Zero based index to specify position of a column with Id identification. This column is optional (-1 means not used) and can be one of the following data type: - String - Guid - Int (32-bit integer value) |
|
PointNamePrefix |
Empty string |
A text, which is added at the beginning of each tag name returned from input table in tag name column. When empty this value is not used. |
This section direct Hyper Reader to read historical aggregates instead of raw values. In general, it needs to know the type of the aggregation and resample period. All other values are optional.
|
Value Name |
Default Value |
Description |
|
AggregateType |
Empty string |
An aggregate type name. Mandatory value, can’t be null or empty. See the next table for possible values. |
|
ProcessingInterval |
0 |
Resample interval in seconds, can’t be less than zero. When zero then one aggregate is calculated for the whole time domain specified as reader’s start and end times. |
|
PercentDataBad |
20 |
Indicates the Maximum percentage of bad data in a given interval above which would cause the StatusCode for the given interval for processed data request to be set to Bad. For values equal to or below this percentage the StatusCode would be Uncertain or Good. For details on which Aggregates use the PercentDataBad Variable, see the definition of each Aggregate. |
|
PercentDataGood |
80 |
Indicates the minimum percentage of Good data in a given interval which would cause the StatusCode for the given interval for the processed data requests to be set to Good. For values below this percentage the StatusCode would be Uncertain or Bad. For details on which Aggregates use the PercentDataGood Variable, see the definition of each Aggregate. |
|
TreatUncertainAsBad |
true |
Indicates how the server treats data returned with a StatusCode severity Uncertain with respect to Aggregate calculations. A value of True indicates the server considers the severity equivalent to Bad, a value of False indicates the server considers the severity equivalent to Good. |
|
UseServerCapabilitiesDefaults |
false |
Use Hyper Historian defaults to calculate aggregated values. |
|
UseSlopedExtrapolation |
false |
When true then use sloped extrapolation (two last known values are used to determine slope), stepped extrapolation otherwise. |
|
Aggregate Type Name |
Description |
|
AnnotationCount |
This Aggregate returns a count of all Annotations in the interval. |
|
Average |
The Average Aggregate adds up the values of all good Raw data for each interval, and divides the sum by the number of good values. If any non-good values are ignored in the computation, the Aggregate StatusCode will be determined using the StatusCode Calculation. This aggregate is not time based so the PercentGood/PercentBad applies to the number of values in the interval. |
|
Count |
The Count Aggregate retrieves a count of all the raw values within an interval. If one or more raw values are non-good, they are not included in the count, and the Aggregate StatusCode is determined using the StatusCode Calculation for non-time based Aggregates. If no good data exists for an interval, the count is zero. |
|
Delta |
The Delta Aggregate retrieves the difference between the earliest and latest good raw values in the interval. The aggregate is negative if the latest value is less than the earliest value. The status is Uncertain_DataSubNormal if non-good values are skipped while looking for the first or last values. The status is Good otherwise. The status is Bad_NoData if no good raw values exist. |
|
DeltaBound |
The DeltaBounds Aggregate returns the difference between the StartBound and the EndBound Aggregates with the exception that both the start and end must be good. If the end value is less than the start value, the result will be negative. If the end value is the same as the start value the result will be zero. If the end value is greater than the start value, the result will be positive. If one or both values are bad the return status will be Bad_NoData. If one or both values are uncertain the status will be Uncertain_DataSubNormal. |
|
DurationBad |
The DurationBad Aggregate divides the interval into regions of bad and non-bad data. Each region starts with a data point in the interval. If that data point is bad the region is bad. The aggregate is the sum of the duration of all bad regions expressed in milliseconds. The status of the first region is determined by finding the first data point at or before the start of the Interval. If no value exists, the first region is bad. Each Aggregate is returned with timestamp of the start of the interval. StatusCodes are Good, Calculated. |
|
DurationGood |
The DurationGood Aggregate divides the interval into regions of good and non-good data. Each region starts with a data point in the interval. If that data point is good the region is good. The aggregate is the sum of the duration of all good regions expressed in milliseconds. The status of the first region is determined by finding the first data point at or before the start of the interval. If no value exists, the first region is bad. Each Aggregate is returned with timestamp of the start of the interval. StatusCodes are Good, Calculated. |
|
DurationInStateZero |
The DurationInStateZero Aggregate returns the time Duration during the interval that the Variable was in the zero state. The Simple Bounding Values for the interval are used to determine initial value (start time <end time) or ending value (if start time > end time) If one or more raw values are non-good, they are not included in the Duration, and the Aggregate StatusCode is determined using the StatusCode Calculation for time based aggregates. Duration is in milliseconds. Unless otherwise indicated, StatusCodes are Good, Calculated. |
|
DurationInStateNonZero |
The DurationInStateNonZero Aggregate returns the time Duration during the interval that the Variable was in the one state. The Simple Bounding Values for the interval are used to determine initial value (start time <end time) or ending value (if start time > end time) If one or more raw values are non-good, they are not included in the Duration, and the Aggregate StatusCode is determined using the StatusCode Calculation (See Clause 5.4.3) for time based aggregates. Duration is in milliseconds. Unless otherwise indicated, StatusCodes are Good, Calculated. |
|
End |
The End Aggregate retrieves the latest raw value within the interval, and returns that value and status with the timestamp at which that value occurs. If no values are in the interval then the StatusCode is Bad_NoData. |
|
EndBound |
The EndBound Aggregate returns the value and status at the EndTime for the interval by calculating the Simple Bounding Values for the interval. The timestamp returned is always the start of the interval. |
|
Interpolative |
The Interpolative Aggregate returns the Interpolated Bounding Value for the startTime of each interval. When searching for Good values before or after the bounding value, the time period searched is a time range which is the size of the ProcessingInterval. |
|
Maximum |
The Maximum Aggregate retrieves the maximum good raw value within the interval, and returns that value with the timestamp at which that value occurs. Note that if the same maximum exists at more than one timestamp, the oldest one is retrieved and the MultipleValues bit is set. Unless otherwise indicated, StatusCodes are Good, Raw. If no values are in the interval no data is returned with a timestamp of the start of the interval. If only bad quality values are available then the status is returned as Bad_NoData. The timestamp of the Aggregate will always be the start of the interval for every ProcessingInterval. |
|
Maximum2 |
The Maximum2 Aggregate retrieves the Maximum good value for each interval as defined for Maximum except that Simple Bounding Values are included. The Simple Bounding Values for the interval are found according to the definition of Simple Bounding Values. Any bad values are ignored in the computation, The Aggregate StatusCode will be determined using the StatusCode Calculation for time based aggregates. If a bounding value is returned then the status will indicate, Raw, Calculated or Interpolated. If TreatUncertainAsBad is false and an Uncertain raw value is the Maximum then that Uncertain value is used. Uncertain values are ignored otherwise. If sloped interpolation is used and the End bound is the Maximum value then End bound is used as the Maximum with the timestamp set to the startTime of the interval. The End bound is ignored in all other cases. |
|
MaximumActualTime |
The MaximumActualTime is the same as the MinimumActualTime Aggregate, except that the value is the maximum raw value within the interval. Note that if the same maximum exists at more than one timestamp, the oldest one is retrieved and the Aggregate Bits are set to MultipleValues. |
|
MaximumActualTime2 |
The MaximumActualTime2 Aggregate retrieves the Maximum good value for each interval as defined for MaximumActualTime except that Simple Bounding Values are included. The Simple Bounding Values for the interval are found according to the definition of Simple Bounding Values. Any bad values are ignored in the computation, The Aggregate StatusCode will be determined using the StatusCode Calculation for time based aggregates. If a bounding value is returned then the status will indicate, Raw, Calculated or Interpolated. If TreatUncertainAsBad is false and an Uncertain raw value is the Maximum then that Uncertain value is used. Uncertain values are ignored otherwise. If sloped interpolation is used and the End bound is the Maximum value then End bound is used as the Maximum with the timestamp set to the EffectiveEndTime of the interval. The End bound is ignored in all other cases. |
|
Minimum |
The Minimum Aggregate retrieves the minimum good raw value within the interval, and returns that value with the timestamp at which that value occurs. Note that if the same minimum exists at more than one timestamp, the oldest one is retrieved and the MultipleValues bit is set. Unless otherwise indicated, StatusCodes are Good, Raw. If no values are in the interval no data is returned with a timestamp of the start of the interval. If only bad quality values are available then the status is returned as Bad_NoData. The timestamp of the Aggregate will always be the start of the interval for every ProcessingInterval. |
|
Minimum2 |
The Minimum2 Aggregate retrieves the minimum good value for each interval as defined for Minimum except that Simple Bounding Values are included. The Simple Bounding Values for the interval are found according to the definition of Simple Bounding Values. Any bad values are ignored in the computation. The Aggregate StatusCode will be determined using the StatusCode Calculation for time based aggregates. If a bounding value is returned then the status will indicate, Raw, Calculated or Interpolated. If TreatUncertainAsBad is false and an Uncertain raw value is the minimum then that Uncertain value is used. Uncertain values are ignored otherwise. If sloped interpolation is used and the End bound is the minimum value then End bound is used as the Minimum with the timestamp set to the startTime of the interval. The End bound is ignored in all other cases. |
|
MinimumActualTime |
The MinimumActualTime Aggregate retrieves the minimum good raw value within the interval, and returns that value with the timestamp at which that value occurs. Note that if the same minimum exists at more than one timestamp, the oldest one is retrieved and the Aggregate Bits are set to MultipleValues. |
|
MinimumActualTime2 |
The MinimumActualTime2 Aggregate retrieves the minimum good value for each interval as defined for Minimum except that Simple Bounding Values are included. The Simple Bounding Values for the interval are found according to the definition of Simple Bounding Values. Any bad values are ignored in the computation, The Aggregate StatusCode will be determined using the StatusCode Calculation for time based aggregates. If a bounding value is returned then the status will indicate, Raw, Calculated or Interpolated. If TreatUncertainAsBad is false and an Uncertain raw value is the minimum then that Uncertain value is used. Uncertain values are ignored otherwise. If sloped interpolation is used and the End bound is the minimum value then End bound is used as the Minimum with the timestamp set to the EffectiveEndTime of the interval. The End bound is ignored in all other cases. |
|
NumberOfTransitions |
The NumberOfTransitions Aggregate returns a count of the number of transition the Variable had during the interval. If one or more raw values are bad, they are not included in the count, and the Aggregate StatusCode is determined using the StatusCode Calculation for non-time based aggregates. The earliest transition must be calculated by comparing the earliest non-bad value in the interval to the previous non-bad value. A transition occurred if no previous non-bad value exists or if the earliest non-bad value is different. The endTime is not considered part of the interval, so a transition occurring at the endTime is not included. Unless otherwise indicated, StatusCodes are Good, Calculated. |
|
PercentBad |
The PercentBad Aggregate performs the following calculation: PercentBad = DurationBad / ProcessingInterval * 100 Where: DurationBad is the result from the DurationBad Aggregate, calculated using the ProcessingInterval supplied to PercentBad call. ProcessingInterval is the duration of interval. If the last interval is a partial interval then the duration of the partial interval is used in the calculation. Each Aggregate is returned with timestamp of the start of the interval. StatusCodes are Good, Calculated. |
|
PercentGood |
The PercentGood Aggregate performs the following calculation: PercentGood = DurationGood / ProcessingInterval * 100 Where: DurationGood is the result from the DurationGood Aggregate, calculated using the ProcessingInterval supplied to PercentGood call. ProcessingInterval is the duration of interval. If the last interval is a partial interval then the duration of the partial interval is used in the calculation. Each Aggregate is returned with timestamp of the start of the interval. StatusCodes are Good, Calculated. |
|
Range |
The Range Aggregate finds the difference between the maximum and minimum good raw values in the interval. If only one Good value exists in the interval, the range is zero. Note that the range is always zero or positive. If non-good values are ignored when finding the minimum or maximum values or if bad values exist then the status is Uncertain_DataSubNormal. |
|
Range2 |
The Range2 Aggregate finds the difference between the maximum and minimum values in the interval as returned by the Minimum2 and Maximum2 Aggregates. Note that the range is always zero or positive. |
|
Start |
The Start Aggregate retrieves the earliest raw value within the interval, and returns that value and status with the timestamp at which that value occurs. If no values are in the interval then the StatusCode is Bad_NoData. |
|
StartBound |
The StartBound Aggregate returns the value and status at the StartTime for the interval by calculating the Simple Bounding Values for the interval. |
|
StdDevPopulation |
The StandardDeviation Population aggregate uses the formula:
Where X is each good raw value in the interval, Avg(X) is the average of the good raw values, and n is the number of good raw values in the interval. For every interval where n=1, a value of 0 is returned. If any non-good values were ignored, the aggregate quality is uncertain/subnormal. All interval aggregates return timestamp of the start of the interval. Unless otherwise indicated, qualities are Good, Calculated. This calculation is for a full population where the calculation is done on the full set of data. Use StdDevSample to calculate the standard deviation of a subset of the full population. An example would be when underlying data collected on an exception basis versus sampled from the data source. |
|
StdDevSample |
The StandardDeviationSample aggregate uses the formula:
Where X is each good raw value in the interval, Avg(X) is the average of the good raw values, and n is the number of good raw values in the interval. For every interval where n=1, a value of 0 is returned. If any non-good values were ignored, the aggregate quality is uncertain/subnormal. All interval aggregates return timestamp of the start of the interval. Unless otherwise indicated, qualities are Good, Calculated. This calculation is for a sample population where the calculation is done on a subset of the full set of data. Use StandardDeviationPopulation to calculate the standard deviation of a full set of data. An example would be when your underlying data is sampled from the data source versus stored on an exception basis. |
|
Sum |
The Sum Aggregate adds up the values of all good Raw data for each interval. If any non-good values are ignored in the computation, the Aggregate StatusCode will be determined using the StatusCode Calculation. This aggregate is not time based so the PercentGood/PercentBad applies to the number of values in the interval. |
|
TimeAverage |
The TimeAverage Aggregate uses Interpolated Bounding Values to find the value of a point at the beginning and end of an interval. Starting at the starting bounding value a straight line is drawn between each value in the interval ending at the ending bounding value (see examples for illustrations). The area under the lines is divided by the length of the ProcessingInterval to yield the average. Note that this calculation always uses a sloped line between points; TimeAverage2 uses a stepped or sloped line depending on what the value of the Stepped Property for the Variable. If one or more Bad Values exist in the interval then they are omitted from the calculation and the StatusCode is set to Uncertain_DataSubNormal. Sloped lines are drawn between the Good values when calculating the area. |
|
TimeAverage2 |
The TimeAverage2 Aggregate uses Simple Bounding Values to find the value of a point at the beginning and end of an interval. Starting at the starting bounding value a straight line is drawn between each value in the interval ending at the ending bounding value (see examples for illustrations). The area under the lines is divided by the length of the ProcessingInterval to yield the average. Note that this calculation uses a stepped or sloped line depending on what the value of the Stepped Property for the Variable; TimeAverage always uses a sloped line between points. The time resolution used in this calculation is server specific. If any non-good data exists in the interval, this data is omitted from the calculation and the time interval is reduced by the duration of the non-good data; i.e. if a value was bad for 1 minute in a 5 minute interval then the TimeAverage2 would be the area under the 4 minute period of good values divided by 4 minutes. If a sub-interval ends at a Bad value then only the Good starting value is used to calculate the area of sub-interval preceding the Bad value. The Aggregate StatusCode will be determined using the time-weighted StatusCode Calculation. |
|
Total |
The Total Aggregate performs the following calculation for each interval: Total = TimeAverage * ProcessingInterval (milliseconds) Where: TimeAverage is the result from the TimeAverage Aggregate, using the ProcessingInterval supplied to the Total call. The resulting units would be normalized to seconds, i.e. [TimeAverage Units] * milliseconds. The Aggregate StatusCode will be determined using the StatusCode Calculation. |
|
Total2 |
The Total2 Aggregate performs the following calculation for each interval: Total2 = TimeAverage2 * ProcessingInterval of Good Data (milliseconds) Where TimeAverage2 is the result from the TimeAverage2 Aggregate, using the ProcessingInterval supplied to the Total2 call. The interval of Good Data is the sum of all sub-intervals where non-bad data exists; i.e. if a value was bad for 1 minute in a 5 minute interval then the interval of Good Data would be the 4 minute period. The resulting units would be normalized to seconds, i.e. [TimeAverage2 Units] * milliseconds. The Aggregate StatusCode will be determined using the StatusCode Calculation. |
|
VariancePopulation |
The VariancePopulation aggregate retrieves the square of the standard deviation. Its behaviour is the same as the StandardDeviationPopulation aggregate. Unless otherwise indicated, qualities are Good, Calculated.
This calculation is for a full population where the calculation is done on the full set of data. Use VarianceSample to calculate the variance of a subset of the full population. |
|
VarianceSample |
The VarianceSample aggregate retrieves the square of the standard deviation. Its behaviour is the same as the StandardDeviationSample aggregate. Unless otherwise indicated, qualities are Good, Calculated. This calculation is for a sample population where the calculation is done on a subset of the full population. Use VariancePopulation to calculate the variance of a full set of data. |
|
WorstQuality |
The WorstQuality Aggregate returns the worst status of the raw values in the interval where a Bad status is worse than Uncertain, which are worse than Good. No distinction is made between the specific reasons for the status. If multiple values exist with the worst quality but different StatusCodes then the StatusCode of the first value is returned and the MultipleValues bit is set. This Aggregate returns the worst StatusCode as the value of the Aggregate. The timestamp is always the start of the interval. The StatusCodes are Good, Calculated. |
|
WorstQuality2 |
The WorstQuality2 Aggregate returns the worst status of the raw values in the interval where a Bad status is worse than Uncertain, which are worse than Good. No distinction is made between the specific reasons for the status. The start bound calculated using Simple Bounding Values is always included when determining the worst quality. If multiple values exist with the worst quality but different StatusCodes then the StatusCode of the first value is returned and the MultipleValues bit is set. This Aggregate returns the worst StatusCode as the value of the Aggregate. The timestamp is always the start of the interval. The StatusCodes are Good, Calculated. |
<SqlServerOutputPluginConfiguration/> Section
This section allows to specify all output Hyper Reader settings – connection to target database, output table names, values and ids column types.
|
Value Name |
Default Value |
Description |
|
ConnectionString |
Empty string |
A connection string to the SQL server database to store output data. |
|
TableName |
Empty string |
A name of the output table to store exported values. This value can be overridden by command line argument –to. |
|
ValueColumnDataType |
String |
A data type of the column to store read values. Can be one of the following values: - String - Variant - Double - Integer |
|
IdColumnDataType |
None |
A data type of Id column, when it isn’t specified then tag name is used instead. Can be one of the following values: - Guid - Integer - String |
|
OutputOptions |
None |
An option to specify how Hyper Reader deals with output table. Can be one of the following values: - Create - DropAndCreate - Append This value can be overridden by command line argument –o. |
|
BulkCopyTimeout |
0 |
Maximum time a batch write can take, in seconds. Valid values are be between 0 and 300. |
|
BatchSize |
20000 |
Maximum amount of data values (records) written to a SQL server output table in a single data batch. Valid values are be between 0 and 100000. |
|
RetryDelay |
15 |
In seconds, specifies for how long Hyper Reader waits between write retries. |
|
RetryCount |
5 |
How many times in a row Hyper Reader tries to write values into a failing database. When this number is reached and data can’t be written then reader stops processing. |
Output table is a database table stored in target database specified by a connection string value. In many cases this table is created by Hyper Reader tool based on configuration settings specified in <SqlServerOutputPluginConfiguration/> section. The only exception is when OutputOption is set to Append mode.
Output database table has to have the following structure, TagName and TagId columns are mutually exclusive:
|
Column Name |
SQL Data Type |
Description |
|
TagName |
nvarchar(255) |
Optional, used when Tag Id is not configured. Always not null. |
|
TagId |
uniqueidentifier int nvarchar(100) |
Optional, when not configured then TagName column is used instead. Data type is specified in IdColumnDataType setting. A value in this column is always not null. |
|
Timestamp |
datetime2 |
A date and time value, maximum precision is 1ms (limited by HH server), always not null. |
|
Value |
sql_variant nvarchar(100) float int |
Depend on ValueColumnDataType configuration setting, can be a null value. |
|
Quality |
bigint |
FwxClient status code stored as 64-bit integer value, always not null. |
In general, when any of the configuration parameter is incorrect then Hyper Reader fails to run and error message(s) are traced to either to TraceWorX or to Windows NT Event log. Message target is specified in Hyper Reader’s application configuration file (see functionality section). Hyper Reader also fails when e.g. output table has invalid format (incompatible data types, missing columns, etc.) and OutputOption is set to append. The same may happen when OutputOptions is set to Create and a table with such name already exists in target database.
Recoverable errors (such as communication issues) are handled by internal recovery mechanism, which retries processing n-times (based on configuration settings) and then stops reading or writing historical data.
When a data conversion is not possible (e.g. Guid to Integer, non-numerical text to Integer or Double, etc.) then particular record is either skipped (target column can’t be null) or a database null value is written instead.
This section describes some basic scenarios that can be used to export data from Hyper Historian Logger to SQL database using Hyper Reader tool. To start Hyper Reader export, XML codded configuration file is necessary. Structure of this file was described in Configuration File section.
The following is sample configuration file distributed in Hyper Reader installation:
<?xml version="1.0" encoding="utf-8"?>
<TaskConfiguration
InputPluginAssembly="HyperReaderPlugins" InputPluginClassName="Ico.HyperReader.Plugins.HyperHistorianInputPluginConfiguration" OutputPluginAssembly="HyperReaderPlugins" OutputPluginClassName="Ico.HyperReader.Plugins.SqlServerOutputPluginConfiguration">
<!-- Input plugin -->
<HyperHistorianInputPluginConfiguration>
<!-- from 0 to Int32.Max, 0 means no limit -->
<ConcurrencyLevel>100</ConcurrencyLevel>
<!-- from 1 to 10000 -->
<MaxValuesPerNode>5000</MaxValuesPerNode>
<!-- Static list of the tags to be read -->
<SourceTags>
<!--
<SourceTag Name="hh:\Configuration\Signals:RampFast" />
-->
</SourceTags>
<!-- Dynamic list of the tags to be read, source is the DB table -->
<SourceTagsLink>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- SQL SELECT query or table name -->
<SqlQuery>Input_table_name</SqlQuery>
<!-- Column index where the tag name is stored -->
<TagNameColumnIndex>0</TagNameColumnIndex>
<!-- Column index where the tag id is stored -->
<TagIdColumnIndex>-1</TagIdColumnIndex>
<!-- Point name prefix -->
<PointNamePrefix>hh:\Configuration\</PointNamePrefix>
</SourceTagsLink>
</HyperHistorianInputPluginConfiguration>
<!-- Output plugin -->
<SqlServerOutputPluginConfiguration>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- Table name where the output is stored -->
<TableName>Output_table_name</TableName>
<!-- Integer, Double, Variant, String -->
<ValueColumnDataType>Variant</ValueColumnDataType>
<!-- None (when Id column is not used), Guid, Integer, String -->
<IdColumnDataType>None</IdColumnDataType>
<!-- Crate, DropAndCreate, Append -->
<OutputOptions>DropAndCreate</OutputOptions>
<BulkCopyTimeout>120</BulkCopyTimeout>
<BatchSize>20000</BatchSize>
</SqlServerOutputPluginConfiguration>
</TaskConfiguration>
In this example, all input tags are configured within configuration file – i.e. no input database is used. Configuration file is configured as the following, file name is configuration_1.xml and it is located in the root of drive c:
<?xml version="1.0" encoding="utf-8"?>
<TaskConfiguration
InputPluginAssembly="HyperReaderPlugins" InputPluginClassName="Ico.HyperReader.Plugins.HyperHistorianInputPluginConfiguration" OutputPluginAssembly="HyperReaderPlugins" OutputPluginClassName="Ico.HyperReader.Plugins.SqlServerOutputPluginConfiguration">
<!-- Input plugin -->
<HyperHistorianInputPluginConfiguration>
<!-- from 0 to Int32.Max, 0 means no limit -->
<ConcurrencyLevel>100</ConcurrencyLevel>
<!-- from 1 to 10000 -->
<MaxValuesPerNode>5000</MaxValuesPerNode>
<!-- Static list of the tags to be read -->
<SourceTags>
<SourceTag Name="hh:\Configuration\Signals:RampFast" />
<SourceTag Name="hh:\Configuration\Signals:SineFast" />
<SourceTag Name="hh:\Configuration\Signals:RandomFast" />
</SourceTags>
<!-- Dynamic list of the tags to be read, source is the DB table -->
<SourceTagsLink>
</SourceTagsLink>
</HyperHistorianInputPluginConfiguration>
<!-- Output plugin -->
<SqlServerOutputPluginConfiguration>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- Table name where the output is stored -->
<TableName>OutputTable</TableName>
<!-- Integer, Double, Variant, String -->
<ValueColumnDataType>Double</ValueColumnDataType>
<!-- None (when Id column is not used), Guid, Integer, String -->
<IdColumnDataType>None</IdColumnDataType>
<!-- Crate, DropAndCreate, Append -->
<OutputOptions>DropAndCreate</OutputOptions>
<BulkCopyTimeout>120</BulkCopyTimeout>
<BatchSize>20000</BatchSize>
</SqlServerOutputPluginConfiguration>
</TaskConfiguration>
Hyper reader reads values from the following data tags, configured in the sample Hyper Historian configuration:
- hh:\Configuration\Signals:RampFast
- hh:\Configuration\Signals:SineFast
- hh:\Configuration\Signals:RandomFast
Read values are stored in HH_IcoUnifiedConfig configuration database, in a table with “OutputTable” name. Configuration without input database table can’t take advantage of tag ids thus values in the output table will be identified by related point names.
To read logged values from May 2nd 2017 to May 3rd 2017 use the following command:
HyperReaderCoreHost.exe -s "c:\configuration_1.xml" -st "2017-05-02" -et "2017-05-03"
Output table may look as shown on the following picture (copied from SQL management studio):
Output Table

Let’s have an input database table defined as shown on the following picture:
Input Database Table
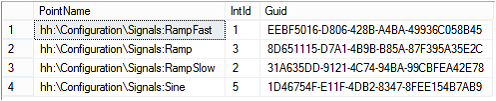
Table name is HReader_PointNames and database name is HH_IcoUnifiedConfig.
Data Tag table with Guid based Id
The following configuration file was used, stored as configuration_2.xml:
<?xml version="1.0" encoding="utf-8"?>
<TaskConfiguration
InputPluginAssembly="HyperReaderPlugins" InputPluginClassName="Ico.HyperReader.Plugins.HyperHistorianInputPluginConfiguration" OutputPluginAssembly="HyperReaderPlugins" OutputPluginClassName="Ico.HyperReader.Plugins.SqlServerOutputPluginConfiguration">
<!-- Input plugin -->
<HyperHistorianInputPluginConfiguration>
<!-- from 0 to Int32.Max, 0 means no limit -->
<ConcurrencyLevel>100</ConcurrencyLevel>
<!-- from 1 to 10000 -->
<MaxValuesPerNode>5000</MaxValuesPerNode>
<!-- Static list of the tags to be read -->
<SourceTags>
</SourceTags>
<!-- Dynamic list of the tags to be read, source is the DB table -->
<SourceTagsLink>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- SQL SELECT query or table name -->
<SqlQuery>HReader_PointNames</SqlQuery>
<!-- Column index where the tag name is stored -->
<TagNameColumnIndex>0</TagNameColumnIndex>
<!-- Column index where the tag id is stored -->
<TagIdColumnIndex>2</TagIdColumnIndex>
<!-- Point name prefix -->
<PointNamePrefix></PointNamePrefix>
</SourceTagsLink>
</HyperHistorianInputPluginConfiguration>
<!-- Output plugin -->
<SqlServerOutputPluginConfiguration>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- Table name where the output is stored -->
<TableName>OutputTable</TableName>
<!-- Integer, Double, Variant, String -->
<ValueColumnDataType>Variant</ValueColumnDataType>
<!-- None (when Id column is not used), Guid, Integer, String -->
<IdColumnDataType>Guid</IdColumnDataType>
<!-- Crate, DropAndCreate, Append -->
<OutputOptions>DropAndCreate</OutputOptions>
<BulkCopyTimeout>120</BulkCopyTimeout>
<BatchSize>20000</BatchSize>
</SqlServerOutputPluginConfiguration>
</TaskConfiguration>
Output table configuration is the same as in previous example. To read logged values from May 2nd 2017 to May 3rd 2017 use the following command:
HyperReaderCoreHost.exe -s "c:\configuration_2.xml" -st "2017-05-02" -et "2017-05-03"
Output table may look as shown on the following picture (copied from SQL management studio):
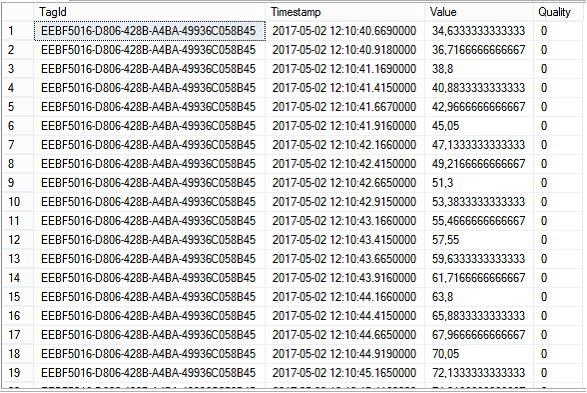
If we modify configuration file from previous example by changing TagIdColumnIndex and IdColumnDataType as shown below, integer based tag id can be used to identify values in the output table:
<?xml version="1.0" encoding="utf-8"?>
<TaskConfiguration
InputPluginAssembly="HyperReaderPlugins" InputPluginClassName="Ico.HyperReader.Plugins.HyperHistorianInputPluginConfiguration" OutputPluginAssembly="HyperReaderPlugins" OutputPluginClassName="Ico.HyperReader.Plugins.SqlServerOutputPluginConfiguration">
<!-- Input plugin -->
<HyperHistorianInputPluginConfiguration>
<!-- from 0 to Int32.Max, 0 means no limit -->
<ConcurrencyLevel>100</ConcurrencyLevel>
<!-- from 1 to 10000 -->
<MaxValuesPerNode>5000</MaxValuesPerNode>
<!-- Static list of the tags to be read -->
<SourceTags>
</SourceTags>
<!-- Dynamic list of the tags to be read, source is the DB table -->
<SourceTagsLink>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- SQL SELECT query or table name -->
<SqlQuery>HReader_PointNames</SqlQuery>
<!-- Column index where the tag name is stored -->
<TagNameColumnIndex>0</TagNameColumnIndex>
<!-- Column index where the tag id is stored -->
<TagIdColumnIndex>1</TagIdColumnIndex>
<!-- Point name prefix -->
<PointNamePrefix></PointNamePrefix>
</SourceTagsLink>
</HyperHistorianInputPluginConfiguration>
<!-- Output plugin -->
<SqlServerOutputPluginConfiguration>
<!-- SQL Server connection string -->
<ConnectionString>
Integrated Security=SSPI;Initial Catalog=HH_IcoUnifiedConfig;
</ConnectionString>
<!-- Table name where the output is stored -->
<TableName>OutputTable</TableName>
<!-- Integer, Double, Variant, String -->
<ValueColumnDataType>Variant</ValueColumnDataType>
<!-- None (when Id column is not used), Guid, Integer, String -->
<IdColumnDataType>Integer</IdColumnDataType>
<!-- Crate, DropAndCreate, Append -->
<OutputOptions>DropAndCreate</OutputOptions>
<BulkCopyTimeout>120</BulkCopyTimeout>
<BatchSize>20000</BatchSize>
</SqlServerOutputPluginConfiguration>
</TaskConfiguration>
Output table configuration is the same as in previous example. To read logged values from May 2nd 2017 to May 3rd 2017 use the following command:
HyperReaderCoreHost.exe -s "c:\configuration_2.xml" -st "2017-05-02" -et "2017-05-03"
Output table may look as shown on the following picture (copied from SQL management studio):
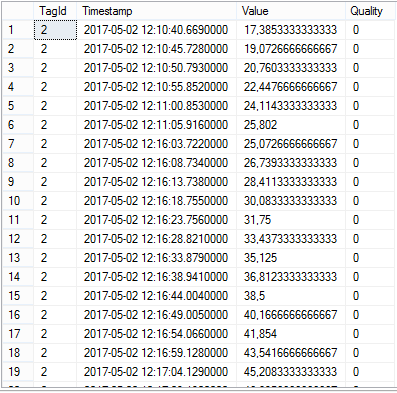
See Also: