|
|
The features on this page require a GENESIS64 Advanced license and are not available with GENESIS64 Basic SCADA . |

![]()
|
|
The features on this page require a GENESIS64 Advanced license and are not available with GENESIS64 Basic SCADA . |
![]()
AnalytiX-BI allows users to configure Extract/Transform/Load (ETL) data flows that read data from physical sources and expose it as processed data sets. Data flows are essentially a sequence of steps, where each step receives data from the previous step and modifies it according to the step’s function.
Typically, a data flow starts with a data source step that reads and transforms data into a tabular dataset. Once data is available in table format it can be further processed if needed. Here are some concrete examples of what it is possible to accomplish using data flows:
Filtering. We are reading a large quantity of historical data and we want to remove records that have NULL values: we can apply a filter that discards such samples.
Shaping. We are reading a table of data from a database, but we only need a few columns: we can drop the unused columns in the data flow.
Processing. We are reading temperature values in Celsius, but we want to consume them as Fahrenheit: we can transform the data using a conversion expression.
Transforming. A web service returns a list of pressure readings as strings, but we want to consume them as doubles: we can apply a data type conversion.
These ETL data flows can then be used as a source for tables in the Data Models, but also consumed from other server applications like BridgeWorX64 or directly from clients like GridWorX Viewer.
For information on how to configure Data Flow Folders, click HERE.
Data Models within AnalytiX-BI have three main purposes:
Give the user the ability to represent a system’s data in a logical way, rather than having to rely on the data’s physical structure
Define relationships between datasets
Query the data in the model using the AnalytiX-BI relational AnalytiX-BI relational query engine
Data Model Architecture
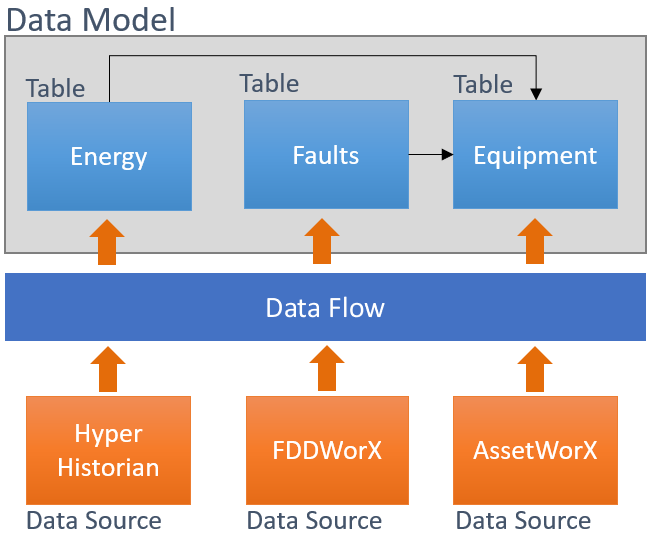
As it is shown in the picture above, a data model is similar in concept to a SQL database – it contains tables (datasets) of data and relationships between tables. Each data table has an associated data flow that describes how to ingest and process the data that is loaded in the table.
For information on how to configure Data Model Folders, click HERE.
See Also: