![]()
![]()
The Hyper Historian to Hyper Historian feature includes multiple benefits, including:
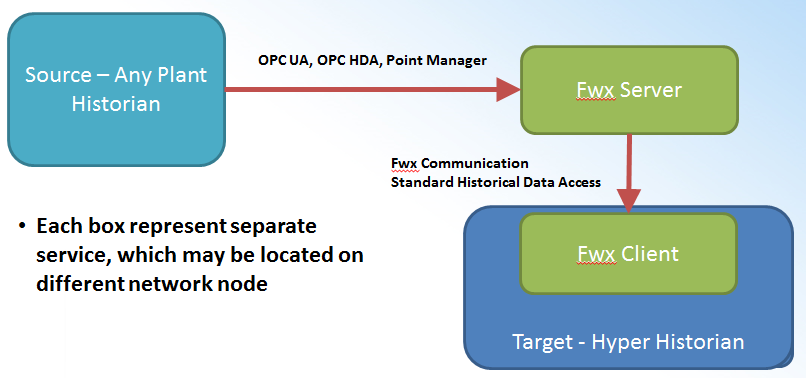
The following image illustrates Basic data flow in Hyper Historian.
Basic Data Flow
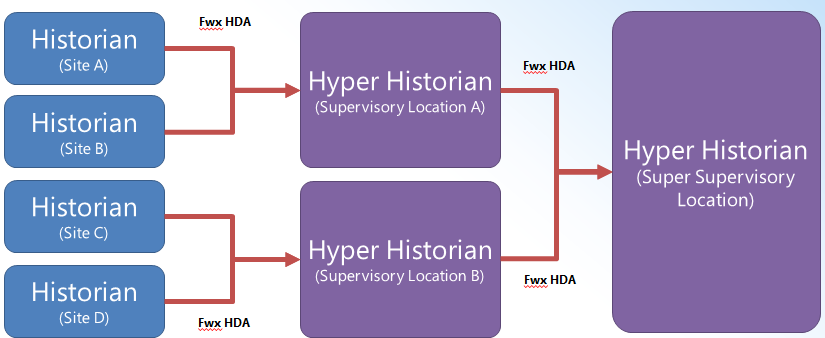
This image shows the Target Hyper Historian Structure.
Target Hyper Historian Structure
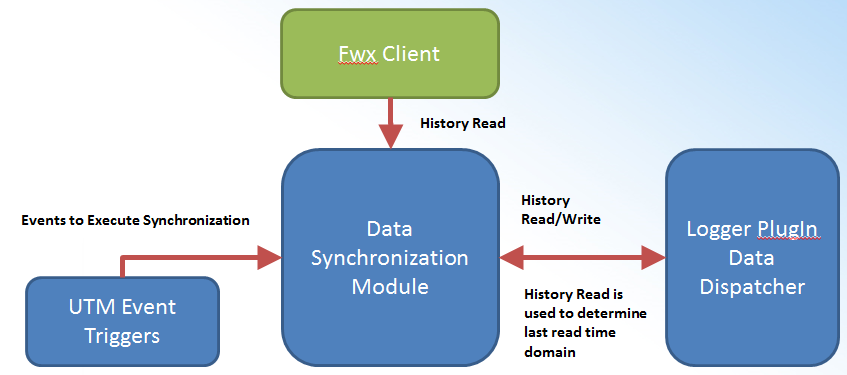
Multi-Tier Synchronization
The Enhanced Data Synchronization available through the Hyper Historian to Hyper Historian feature provides the ability detect changes done after synchronization. It requires support from a Source Historian Server and is supported for Hyper Historian to Hyper Historian connections only. Third-party historian servers can utilize manual data synchronization.
The design of the Enhanced Data Synchronization includes "data modification snapshots". Each time values are inserted or deleted for a particular tag, a new record is added to the snapshot historical database (modified time-domain, type of modification). The snapshot data is exposed as a property within the source data tag. The target historian reads the snapshot info first, then the historical data (if needed).
Snapshot Processing Architecture
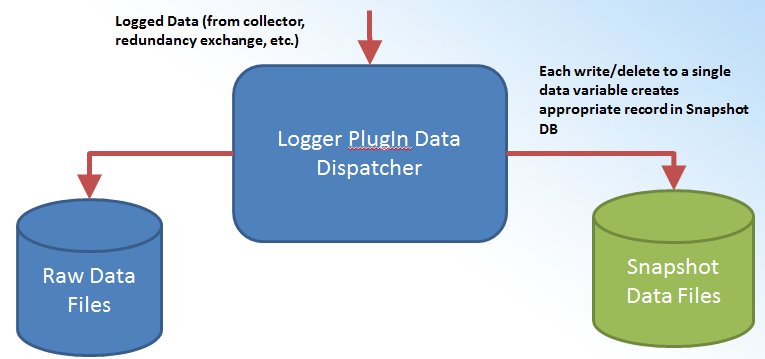
Snapshot processing involves a snapshot database (standard Hyper Historian Logger [file logger]). This contains data for synchronization purposes only. The processing involves short-term, persistent storage (one day, one week), and doesn't require archiving. The snapshot data is available as a property data variable on a source (raw) data variable. Group-level settings are optional.
Synchronization triggered by UTM events
Can be used for any historian server
Doesn't recognize changes in history done after synchronization (re-synchronization requires user interaction)
Currently supported by Hyper Historian only
Can be triggered either by UTM or by changes in source historian
Recognizes changes in history done after synchronization
Both scenarios support manually entered re-synchronization tasks.
See Also:
Hyper Historian to Hyper Historian Set Up