|
|
Available with GENESIS64 Basic SCADA. |

![]()
|
|
Available with GENESIS64 Basic SCADA. |
![]()
MergeWorX is a tool for automatically or manually inserting data into Hyper Historian. It is typically used for importing historical or log data from databases, other historians, intermittently-connected field devices, and other equipment such as PLCs, providing high resolution recording from these devices and greatly increased reliability of capturing all data, even when network outages occur.
MergeWorX uses a plug-in technology you can use to import from various formats of CSV files. You can also write your own .NET plug-in module to read data from any desired data source. You configure the plug-in in the MergeWorX configuration database using Workbench for Desktop. MergeWorX can be configured to process and merge device data in a way that is similar to how OPC servers process data. This includes name mapping, data conversion, scaling, and clamping. The end result is logged data that looks and behaves like it was logged in real time using the standard Hyper Historian Logger. Users can replay the data within the TrendWorX64 Viewer for example, or report on it using ReportWorX.
All MergeWorX communications run through FrameWorX server (or platform services) and can therefore operate remotely from Hyper Historian. Depending on the plug-in type being used, it is possible to be remote from your data source as well.
MergeWorX is an event-driven tool and uses ICONICS' Unified Data Manager (UDM) triggers for initiating data-merging. Currently there are two types of triggers: time-based and data-driven. This allows you to automate data merges for unattended operation, while still giving you the option to manually initiate data merges simply with the click of a button. Consequently, you can have multiple instances of the same plug-in, each fired by its own trigger, and each processing data from a different PLC, device, or source.
MergeWorX processes new data as it receives it and if any errors are encountered (for example it failed to write data to historian server), it sends messages to the GenEvent server to report on the status of its activities.
|
|
Note: MergeWorX is a tool and as such is not designed to process extremely large amounts of data. Its main purpose is to provide a simple way to import and process data that failed to get into Hyper Historian server in a standard way. Even though there are no strict limits on the amount of data that can be processed, there are some limitations in the configuration of communication buffers, plug-ins implementation, CPU, and memory size. As a result, this tool processes data more slowly than Hyper Historian. Keep this in mind when using it to store live data in Hyper Historian. |
The MergeWorX engine uses plug-ins to get data from different sources. It has a Merge module for each plug-in instance. The Merge module consists of a Processing module and Output module. Together, these modules are responsible for data retrieval and confirmation in the plug-in, as well as sending the data to Hyper Historian. The Processing module does all necessary data conversion, scaling, and clamping according to configuration.
MergeWorX Runtime Architecture
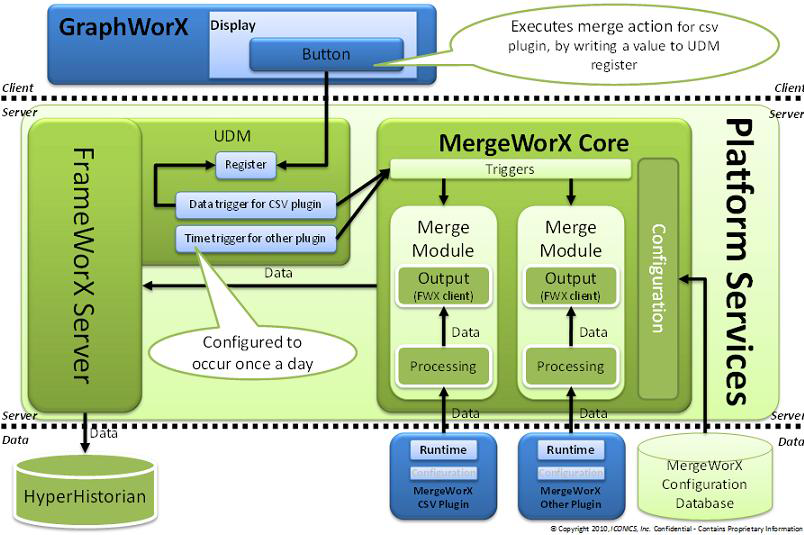
Each Merge module has its own trigger, and is triggered on its own. Upon a trigger event, MergeWorX makes a call to the plugin for available data. After the data is processed (successfully or not) the plugin is called again to confirm the data has been processed. This round trip is done repeatedly as long as the plugin returns some data. Once the pluging returns no data, the merging process stops until a new event trigger has occurred.
The triggering mechanism uses GENESIS64 Triggers. The user needs to configure and associate MergeWorX plugins with triggers that will trigger merging action. There are a variety of types of triggers available, including: alarm, database, date/time, data, file, and NT event. The triggers must be of event type (conditional type is not supported). For manual action execution, the user can create a writeable Unified Data Manager (UDM) register that will be watched by a data trigger. This data trigger will fire an event on any data change in the register.
The user can use a GraphWorX display with a button that writes a new value to the UDM register. For automatic action execution, the user can create a time trigger that periodically fires events (for example it can fire an event every hour). Similarly, the other trigger types can be used for automatic execution based on alarms, database changes, file system changes, or system events.
Configuration of MergeWorX is done through Workbench for Desktop (WBD). The user creates a configuration database for the MergeWorX engine and defines the plugin instances. Each plugin instance must have a trigger defined. On the screen of plugin instances, there is also a plugin specific part. This part is a dialog retrieved from the plugin. It is using a list of generic settings. A setting is a pair of setting name and value. All of these settings are stored in the MergeWorX database and are provided during runtime to the plugin. The setting type also includes a byte array, allowing you to store any configuration.
MergeWorX Configuration Architecture
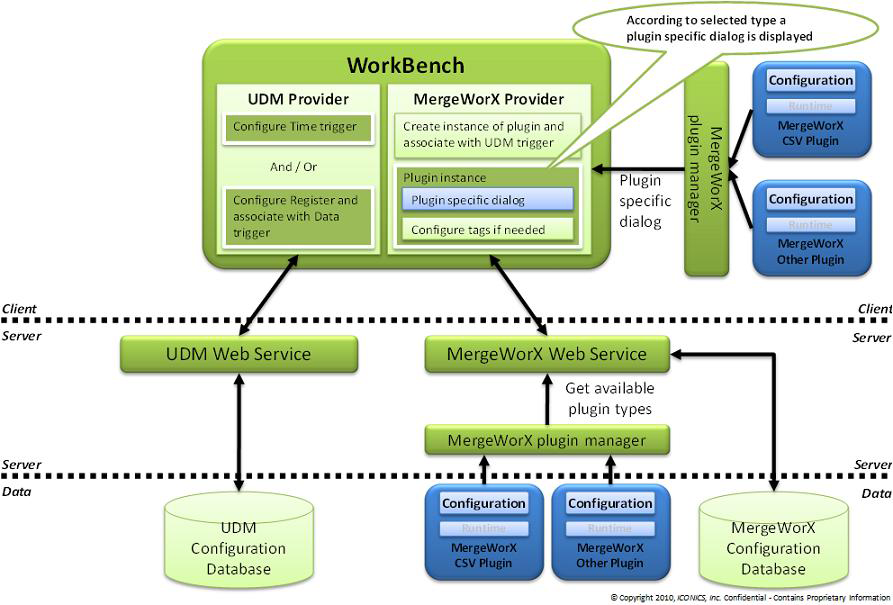
MergeWorX can be configured to process the device data that is being merged in a similar way to how OPC servers process data. This includes name mapping, data conversion, scaling, and clamping. When the MergeWorX engine receives the data, it tries to process it. If the point identification does not match any of the MergeWorX configured Tag’s input names, it simply leaves out the processing when it sends the output.
The plugin configuration also includes a setting called output node. The idea is that you can specify the Hyper Historian (HH) node name and then omit, in the Tag configuration, the node name part of browse path. The MergeWorX engine will join the two (Hyper Historian node name and Tag name) during the processing. This allows you to easily switch to a different HH node (with same configuration) by changing a single setting.
Note: the output node name also plays a role for non-configured tags. This means that the output node name will be added also to all non-configured points returned by plugins.
See also: