Note: This tool is recommended for advanced users only.
Unlike previous tools, HHSplitter.exe tool allows to manage historical data files generated by Hyper Historian logger and it is expected to be used by advanced Hyper Historian users (system administrators, integrators, etc.). Thus, its successful usage requires relatively deep knowledge of the data stored in these files.
Data storage files (.hhd) are internally organized in “data slots” – in data segments of the same size. Each data slot can hold data of a single data point. Each data point is uniquely identified by a GUID (globally unique identifier) number.
The very first data slot is the header of a file, and its size is always 4kB. It contains the information about version, data slot sizes, time domain (data start and end times), etc. The standard data slot size is 4kB, too but it can be configured between 1kB and 256kB. Once data file is created, the header info cannot change – i.e., the data slot size cannot change. The overall time-domain is fixed, too. If a single value is bigger than data slot size, “data slot chaining” applies – multiple data slots can be linked together.
Each of the configured Data Loggers creates its own set of data files (hhd files).
To reorganize data files, this tool always uses active Hyper Historian configuration data. The following section describes all features supported by this tool where the described features may apply together on input data files, depending on the differences between the original and the target configurations. Please note that the selected processing mode can limit the number of supported features.
Allows to merge data files generated by multiple logger instances into a single logger instance. It can be useful when e.g., a user finds out that data files (hhd) are too small and there is no need for keeping data in multiple file sets generated by multiple loggers.
Logged data can be divided into multiple data files – data logged by one data logger instance can be split across multiple logger instances. It is useful for a situation when e.g., the logger generates too big files and it can be useful to divide them into multiple logger instances. The other reason can be separating calculated or aggregated values into long term storages – each logger instance can manage its archive settings.
If it is necessary to either prolong or shorten time domain of data files, e. g. when data files were created with daily granularity and now it is requested to use monthly.
As mentioned earlier, data slot size is applied when a new file is created. Thus, to modify it, a new data file must be created. This tool always creates new data files based on old data, so it is currently the only way to modify it.
Sometimes it can be useful to shrink the data file size by removing unused data slots. It may happen e.g., in case of calculated data when the values are frequently recalculated with different granularity – i.e., triggered at a different time point due to either configuration changes or when data triggers are used. It can also handle is the removal of the data slots that do not have the related data point configured – in case a data point was removed from configuration.
To have corrupted data slots is a very rare case. Hyper Historian has a mechanism (file journaling, NTFS transactions) how to prevent such issues. However, broken HDDs or other host system related issues may damage the data files. Hyper Historian has an auto-reindexing feature which hides such data slots when they are detected. However, this tool removes corrupted data slots from data files.
If the logger configuration is modified (data point ids had changed) or if we need to map data for the same point(s) logged under different GUIDs, this feature can help. It allows to remap one GUID to another GUID data point identifier. In order to do it, the user must create a mapping file – a simple text file where each line contains a source and target ids separated by a tab character. Such file can be auto-generated (part of this tool) from two configuration databases and id pairs are created based on data point name matching.
This tools always reads existing data files (.hhd) and creates new data file(s) with a re-organized data structure. New data structure is based on an existing active Hyper Historian configuration.
It has two basic modes – faster mode, marked as “Split Archives Only” (default option) and “Full Archive Rearrange” mode (unchecked “Split Archives Only”).
This mode is faster when re-arranging data files but it has a limited functionality. If this mode is selected, the data in data slots are not validated (not fully deserialized) and the newly created file/s is/are filled in the same binary form of read data slots. Thus, it doesn’t allow to change data slot sizes, and existing files can be either divided into multiple data files or/and re-arranged based on the current Hyper Historian logger configuration. It can be useful in cases when administrators want to change an existing configuration to use more logger instances to redistribute the IO load for loggers, reduce data file sizes or/and change data file time domains. In general, it supports the following features:
Data file split (single logger into multiple loggers)
Time-domain changes
Full archive re-arrange reads the data from data files and deserializes data slots down to separate values. All values are then written to newly created data files in the same way that the logger uses for standard data logging. Data processing is slower than in the previous mode. However, it supports a full set of re-arrange functionalities:
Data file merge (multiple loggers into single logger)
Data file split (single logger into multiple loggers)
Time-domain changes
Data slot size changes
Unused data slots removal (deleted data slots, etc.)
Removing of corrupted data slots
Data point GUID re-mapping
Do not run this tool on nodes where Hyper Historian Logger is up and running. Either stop this service before using it or copy data files to a different network node.
Make sure correct Hyper Historian configuration is active.
Target file storage must have enough free space available – roughly greater or equal to the sum of all input file sizes.
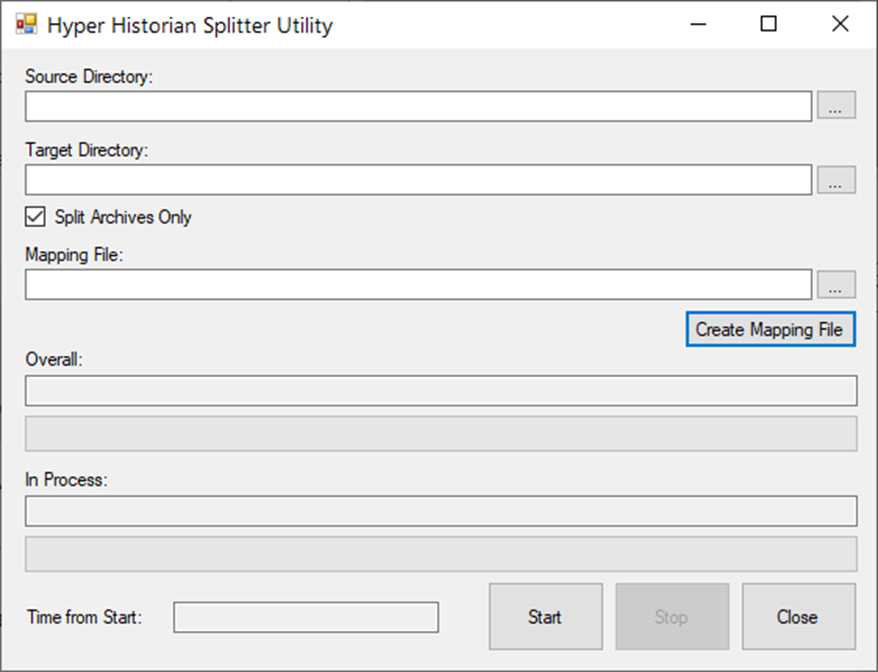
Specify “Source Directory” by typing it in or by selecting it in the browser. This directory must contain some data files to be converted (source data files).
Specify “Target Directory” by typing it in or by selecting it in the browser. Output directory is the place where new data files are created. Source and Target directories cannot point to the same file directory location!
Specify conversion mode – “Split Archives Only” or “Full Archive Rearrange”. The default value is “Split Archives Only” – checkbox with the same name is checked.
If needed, then select data point GUIDs mapping file. This file can be auto-generated based on old and new Hyper Historian configurations – the “Create Mapping File” button. Since the generated file is textual, it is relatively easy to modify it by hand (or by merging multiple conversion files into a single file).
Run the current conversion by clicking on the “Start” button. The operation can be stopped at any time by clicking on the “Stop” button. The progress of overall and each source data file conversion is displayed in progress bars located between the “Create Mapping File” and “Start/Stop” buttons. It also shows the currently processing file name.
As mentioned earlier, mapping file is a text file where each line contains a pair of GUID values separated by a TAB character – source and target ids. This file can be autogenerated. To do this, use the “Create Mapping File” button. After that the following dialog appears:
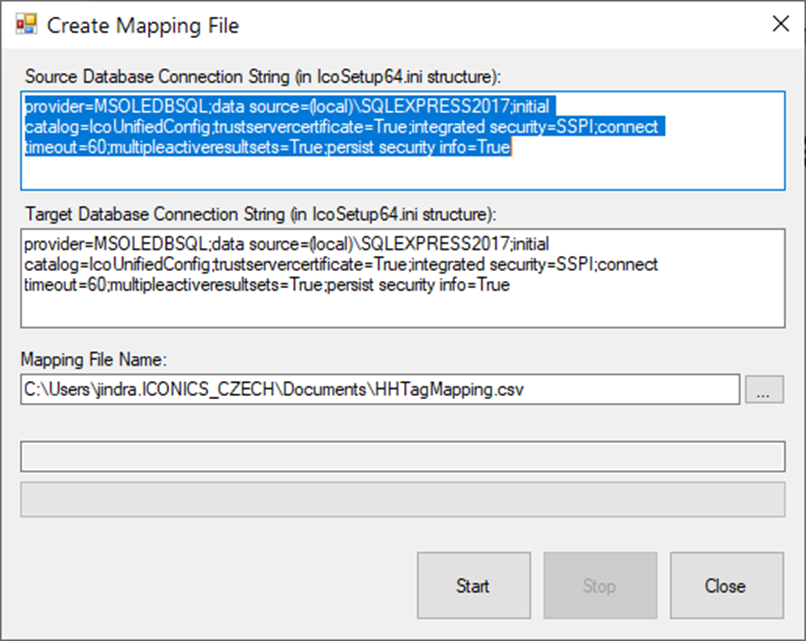
To simplify the mapping file tool’s configuration, source and target database connection strings are prefilled by the current active database connection string. These strings (or at least one of the strings) must be modified to point to correct source and target the configuration databases.
The mapping file name is also pre-filled and can be modified if needed. By clicking on the “Start” button, this tool starts the processing of source and target databases. An example of auto-generated file is shown in the picture below. In this file, the third column also contains the data point name which was used for id matching. The point name is there for information purposes only and it is ignored by splitter tool.