The Hyper Historian installation initializes the Node Setup and Redundancy configuration. Its default settings are for a non-redundant single workstation setup (that is, a non-redundant Hyper Historian Logger with one local Collector).
The Node Setup and Redundancy configuration forms are used to perform any of the following changes:
Change the name or description of a Collector or a Logger
Add or Delete Remote Collector(s) (Enterprise Edition)
Specify the redundancy settings for a Collector (Enterprise Edition)
Specify the redundancy settings for a Logging Server (Enterprise Edition)
Configure the memory cache size for each collector
NOTE: For additional information about Remote Collectors, refer to the Remote Collectors topic. For information about redundancy for OPC UA servers, refer to the Redundancy Setup Options in Hyper Historian topic.
To Configure Redundancy and Store-and-Forward Options for a Collector:
Start the Workbench, then expand your project. Next, expand the Historical Data node to show the Hyper Historian node. Expand the Hyper Historian node to show the Node Setup and Redundancy node.
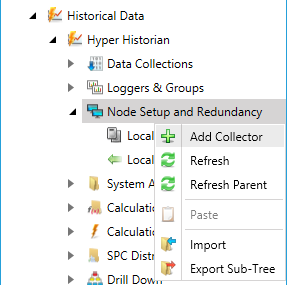
Right-click Node Setup and Redundancy in the navigation tree and select Add Collector, as shown below, or double-click an existing collector to edit it.
Add Collector from Project Explorer
-OR-
Select Node Setup and Redundancy, then click on the Add Collector button, shown below, in the Edit section of the Home ribbon in the Workbench.
Add Collector Button

The Hyper Historian Collector Form appears. Enter a name for the collector in the Hyper Historian Collector Name text entry field.
Hyper Historian Collector Form - Properties Tab
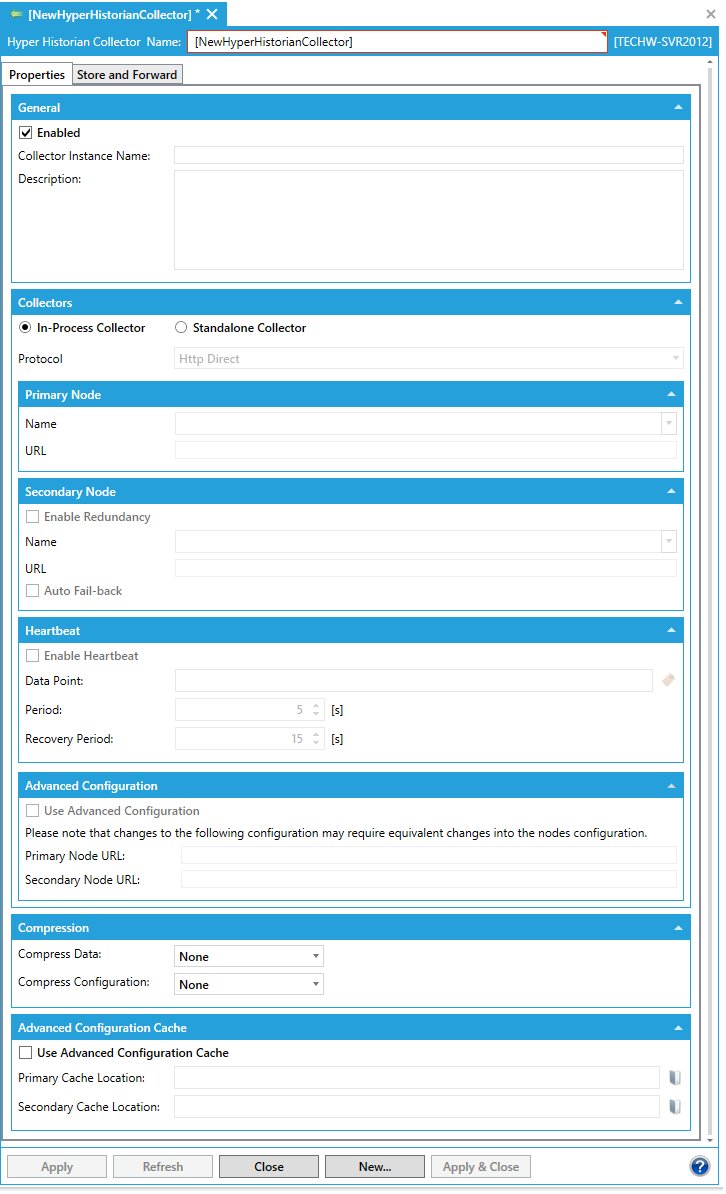
Ensure that the Enabled check box is checked.
Enter a Collector Instance Name in the following text entry field.
Enter a Description, making it informative enough so that anyone maintaining the collector will understand its use.
Next, you select either In-Process Collector (to run the "local" collector) or Standalone Collector (to run the "remote" collector). Click the radio button next to your desired choice.
|
|
Note: Hyper Historian will not run with Standalone/Remote Collectors if used with a Standard License. Only users with an Enterprise License can use this type of collector. |
If you selected In-Process Collector, the local collector is used. If you selected Standalone Collector, you must do the following:
Use the Protocol drop-down list to select from Http Direct, Tcp Direct, Http over FrameWorX, Tcp over FrameWorX, Https over FrameWorX, WSHttps over FrameWorX, or Use Local FrameWorX as Mediator.
Enter a Name for the Primary Node or select one from the drop-down list. The URL field is pre-filled from your primary node selection.
You now have the option to click the Enable Redundancy check box within to Secondary Node to identify a backup node in case the primary node becomes unavailable. The following steps assume you have proceeded with configuring a backup node.
Enter a Name for the Secondary Node or select one from the drop-down list. The URL field is pre-filled from your backup node selection. (Alternatively, you can use the Advanced Configuration option at the bottom of the form to manually enter the URLs of the primary and secondary nodes.)
Click the check box next to Auto Fail-back if you want Hyper Historian to automatically switch from the backup (secondary) node to the primary node when the primary node becomes active again.
Click the Enable Heartbeat checkbox to enable a heartbeat for the given collector.
Enter a data point for the heartbeat in the Data Point text entry field or click on the  button to open the data browser to navigate to your selected data point.
button to open the data browser to navigate to your selected data point.
In the Period text entry field, enter the heartbeat period for failure detection (in seconds).
In the Recovery Period text entry field, enter the period for the recovery after heartbeat failure (in seconds).
Click the checkbox next to Use Advanced Configuration to manually specify node URLs (and allow further configuration). You can then specify the primary node URL in the Primary Node URL text entry field. If you clicked the Enable Redundancy checkbox in the Secondary Node section, you can also specify the secondary node URL in the Secondary Node URL text entry field.
The Compress Data pulldown menu sets the type of compression of the logged data. None = no compression. DeflateFlat = Fast compression using the Deflate algorithm. DeflateOptimal = Optimal compression using the Deflate algorithm.
The Compress Configuration pulldown menu sets the type of compression of the configuration data. None = no compression. DeflateFlat = Fast compression using the Deflate algorithm. Optimal = Optimal compression using the Deflate algorithm.
Click the check box next to Use Advanced Configuration Cache to manually specify the location of the configuration cache (and allow further configuration). You can specify the location of the configuration cache on the primary node by entering it in the Primary Cache Location text entry field or click on the  button to open the Browse files or folders window to navigate to your desired location. If you clicked the Enable Redundancy checkbox in the Secondary Node section, you can also specify the location of the configuration cache on the secondary node in the Secondary Cache Location text entry field or click on the button to open the Browse files or folders window to navigate to your desired location.
button to open the Browse files or folders window to navigate to your desired location. If you clicked the Enable Redundancy checkbox in the Secondary Node section, you can also specify the location of the configuration cache on the secondary node in the Secondary Cache Location text entry field or click on the button to open the Browse files or folders window to navigate to your desired location.
Go to the Store and Forward tab. The Store and Forward feature caches data if the connection to a collector is lost. When the connection to the collector is restored, the cache will be flushed, and the two (primary and secondary) databases will be automatically synchronized.
Hyper Historian Collector Properties - Store and Forward Tab
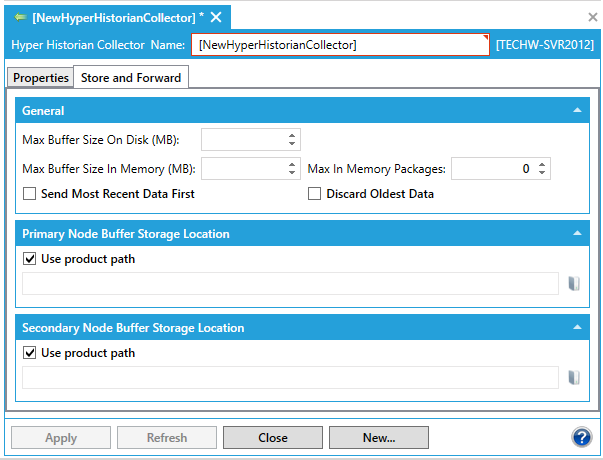
Enter your Store and Forward settings, which are:
Max Buffer Size on Disk (MB) - Enter the maximum disk space (in megabytes) that the buffer can use to store packages.
Max Buffer Size in Memory (MB) - Enter the maximum amount of memory that can be used by the data buffer (in megabytes) to store data packages.
Max in Memory Packages - Enter the maximum number of data packagers that can be stored in memory. Set to zero for no limit.
Send Most Recent Data First - Click this checkbox if you want the most recently collected data to be stored and forwarded before all other data.
Discard Oldest Data - Click this checkbox to discard the oldest data first. Leave it empty to discard the newest data first (this is the default selection).
Use product path - This checkbox is enabled by default to use the product path as the Buffer Storage Location for the Primary Node. This is the location where data will be queued for storage. Deselecting the checkbox allows you to enter a location in the text entry field that appears or, by clicking on the button, to navigate to a location via the Browse files or folders window.
Use product path - This checkbox is enabled by default to use the product path as the Buffer Storage Location for the Secondary Node. This is the location where data will be queued for storage. Deselecting the checkbox allows you to enter a location in the text entry field that appears or, by clicking on the button, to navigate to a location via the Browse files or folders window.
Click the Apply button to save your changes.
Note that, alternatively, you can import collector node configuration information from an Excel spreadsheet, an XML file, or a CSV file. For more information, refer to the Importing and Exporting Hyper Historian Configurations topic. Once imported, you can edit imported information as needed.
To Configure Redundancy and Store-and-Forward Options for the Local Logging Server:
Start the Workbench, then expand your project. Next, expand the Historical Data node to show the Hyper Historian node. Expand the Hyper Historian node to show the Node Setup and Redundancy node.
Expand the Node Setup and Redundancy node. Right-click the Local Logger Server node in the navigation tree and select Edit or Edit on a new tab, as shown below.
Edit Local Logging Server from Project Explorer

-OR-
Select the Local Logging Server, then click on the Edit button, shown below, in the Edit section of the Home ribbon in the Workbench.
Edit Button
This opens the Local Logging Server properties, as shown below.
Local Logging Server Properties
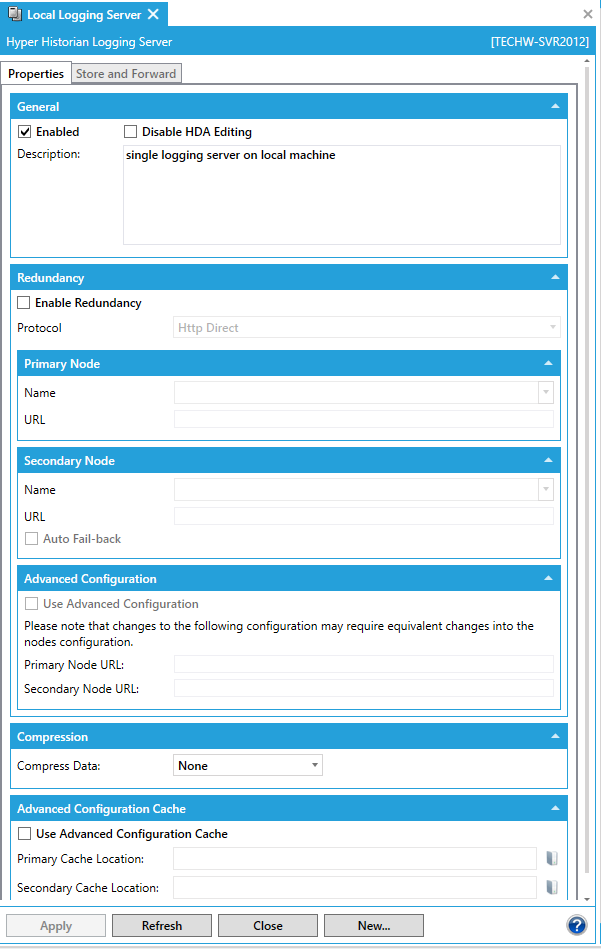
Ensure the Enabled check box is checked.
Optionally, to make the server's historical data read-only, put a check mark in the Disable HDA Editing check box. If you do this, you won't be able to edit any Historical data being logged on the server using any programmatic interfaces.
Enter the optional Description, if desired.
To use redundancy, click the check mark next to Enable Redundancy to enable it, and follow these steps:
Use the Protocol drop-down list to select from Http Direct, Tcp Direct, Http over FrameWorX, Tcp over FrameWorX, Https over FrameWorX, WSHttps over FrameWorX, or Use Local FrameWorX as Mediator.
Enter a Name for the Primary Node or select one from the drop-down list. The URL field is pre-filled from your primary node selection.
You now have the option to click the Enable Redundancy check box within to Secondary Node to identify a backup node in case the primary node becomes unavailable. The following steps assume you have proceeded with configuring a backup node.
Enter a Name for the Secondary Node or select one from the drop-down list. The URL field is pre-filled from your backup node selection. (Alternatively, you can use the Advanced Configuration option at the bottom of the form to manually enter the URLs of the primary and secondary nodes.)
Click the check box next to Auto Fail-back if you want Hyper Historian to automatically switch from the backup (secondary) node to the primary node when the primary node becomes active again.
Click the checkbox next to Use Advanced Configuration to manually specify node URLs (and allow further configuration). You can then specify the primary node URL in the Primary Node URL text entry field. If you clicked the Enable Redundancy checkbox in the Secondary Node section, you can also specify the secondary node URL in the Secondary Node URL text entry field.
The Compress Data pulldown menu sets the type of compression of the logged data. None = no compression. DeflateFlat = Fast compression using the Deflate algorithm. DeflateOptimal = Optimal compression using the Deflate algorithm.
The Compress Configuration pulldown menu sets the type of compression of the configuration data. None = no compression. DeflateFlat = Fast compression using the Deflate algorithm. Optimal = Optimal compression using the Deflate algorithm.
Click the check box next to Use Advanced Configuration Cache to manually specify the location of the configuration cache (and allow further configuration). You can specify the location of the configuration cache on the primary node by entering it in the Primary Cache Location text entry field or click on the button to open the Browse files or folders window to navigate to your desired location. If you clicked the Enable Redundancy checkbox in the Secondary Node section, you can also specify the location of the configuration cache on the secondary node in the Secondary Cache Location text entry field or click on the button to open the Browse files or folders window to navigate to your desired location.
Go to the Store and Forward tab. The Store and Forward feature caches data if the connection to a local logging server is lost. When the connection to the collector is restored, the cache will be flushed, and the two (primary and secondary) databases will be automatically synchronized.
Hyper Historian Local Logging Server Properties - Store and Forward Tab

Enter your Store and Forward settings, which are:
Max Buffer Size on Disk (MB) - Enter the maximum disk space (in megabytes) that the buffer can use to store packages.
Max Buffer Size in Memory (MB) - Enter the maximum amount of memory that can be used by the data buffer (in megabytes) to store data packages.
Max in Memory Packages - Enter the maximum number of data packagers that can be stored in memory. Set to zero for no limit.
Send Most Recent Data First - Click this checkbox if you want the most recently collected data to be stored and forwarded before all other data.
Discard Oldest Data - Click this checkbox to discard the oldest data first. Leave it empty to discard the newest data first (this is the default selection).
Use product path - This checkbox is enabled by default to use the product path as the Buffer Storage Location for the Primary Node. This is the location where data will be queued for storage. Deselecting the checkbox allows you to enter a location in the text entry field that appears or, by clicking on the button, to navigate to a location via the Browse files or folders window.
Use product path - This checkbox is enabled by default to use the product path as the Buffer Storage Location for the Secondary Node. This is the location where data will be queued for storage. Deselecting the checkbox allows you to enter a location in the text entry field that appears or, by clicking on the button, to navigate to a location via the Browse files or folders window.
[Click HERE for more info on Store and Forward settings.]
Click the Apply button to save your changes.
Note that, alternatively, you can import logging server configuration information from an Excel spreadsheet, an XML file, or a CSV file. For more information, refer to the Importing and Exporting Hyper Historian Configurations topic. Once imported, you can edit imported information as needed.
See Also: