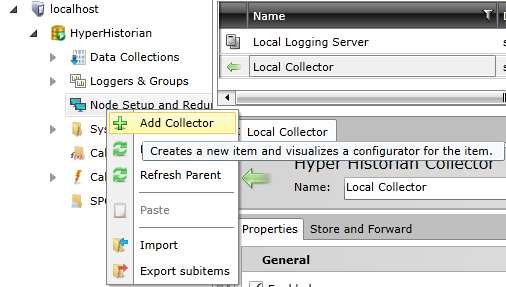
Hyper Historian is separated into two parts: data collection and data logging. While you can have only one logging server for non-redundant setup, multiple collectors can sample data for you.
Using a remote collector could potentially cut down on your network traffic. Consider a scenario where you are collecting data every second and using a calculation period of one minute to find the maximum value for the minute. If your OPC server is remote, then, it will have to forward a sample to the local collector every second. However, if you put the collector on the remote machine where the OPC server resides, it would only need to send the calculated value to the logger once a minute. With this setup, the amount of network traffic decreases to one value per minute as opposed to one value per second.
You can take advantage of this type of setup if you have Hyper Historian Enterprise Edition licensing. This document walks you through the steps to setting up a remote collector.
In order for a remote collector to work properly, the time on all computers in question must be synchronized. This means the computer running the collector should have the same time as the computer that is running the logger.
There are a couple of ways to synchronize the time on your machines:
You can find more information on how to synchronize the time on different machines in the Synchronizing Machine Time topic.
To make sure the computers can communicate with each other, you should turn off Windows Firewall or create an exception for the ports that the collectors are using. You may also want to turn off Windows User Account Control (UAC), as it could also hinder application communication.
With these general settings applied, you should be ready to start configuring your remote collector.
For Hyper Historian Logger, a complete Hyper Historian installation must be installed on the machine. There can be only "local" Loggers.
For a remote Hyper Historian Collector, you can use a standalone Hyper Historian Collector installation, which is available on the Hyper Historian DVD. You can also use a remote collector on a complete Hyper Historian installation.
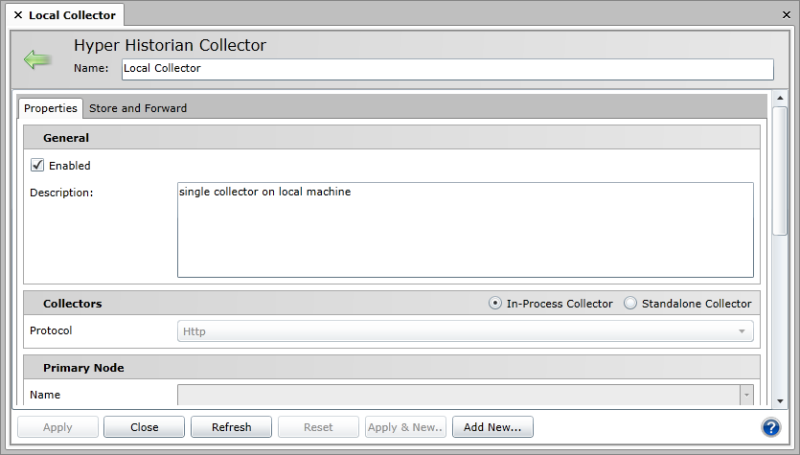
To set up a local collector configuration:
Hyper Historian Local Collector
Remote Collector Configuration
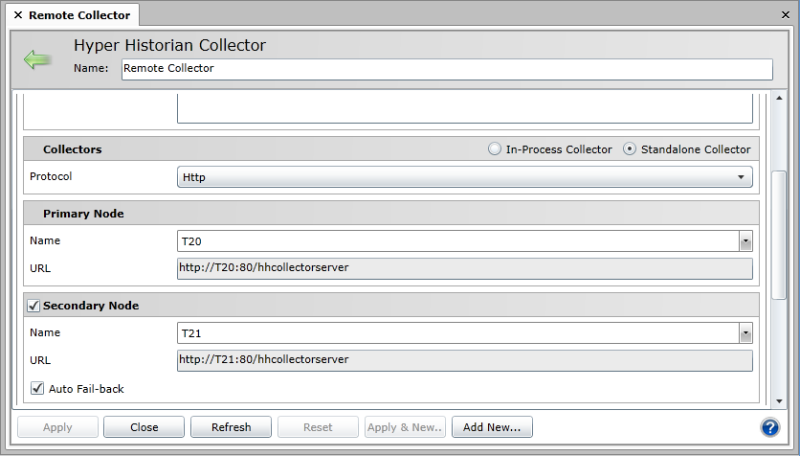
Enter a Name for the Primary Node or select one from the drop-down list. The URL field is pre-filled from your primary node selection. (Alternatively, you can check the Use Advanced Configuration option at the bottom of the form to manually enter the URL of the primary node. See step f. below.)
You now have the option to click the check box next to Secondary Node to identify a backup node in case the primary node becomes unavailable. The following steps assume you have proceeded with configuring a backup node.
Enter a Name for the Secondary Node or select one from the drop-down list. The URL field is pre-filled from your backup node selection. (Alternatively, you can check the Use Advanced Configuration option at the bottom of the form to manually enter the URL of the secondary node. See step f. below.)
Enable the check box next to Auto Fail-back if you want Hyper Historian to automatically switch from the backup (secondary) node back to the primary node when the primary node becomes active again.
Click the check box next to Use Advanced Configuration to allow further configuration. Once the box is checked, you can enter both the Primary Node URL and Back Node URL directly (rather than relying on the dialog to fill them in as you configure the Primary Node and Secondary Node sections). Note that changes to this configuration may require you to make the same changes in the nodes configuration.
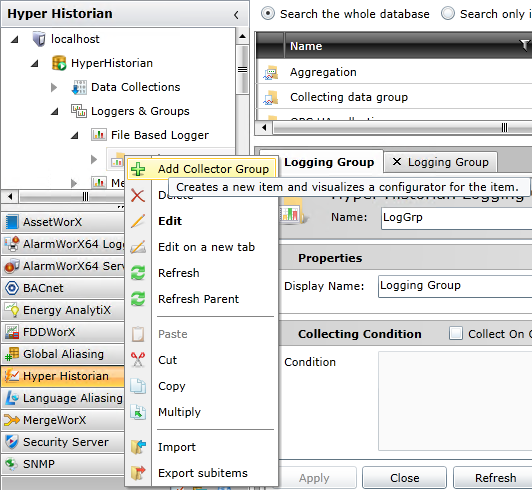
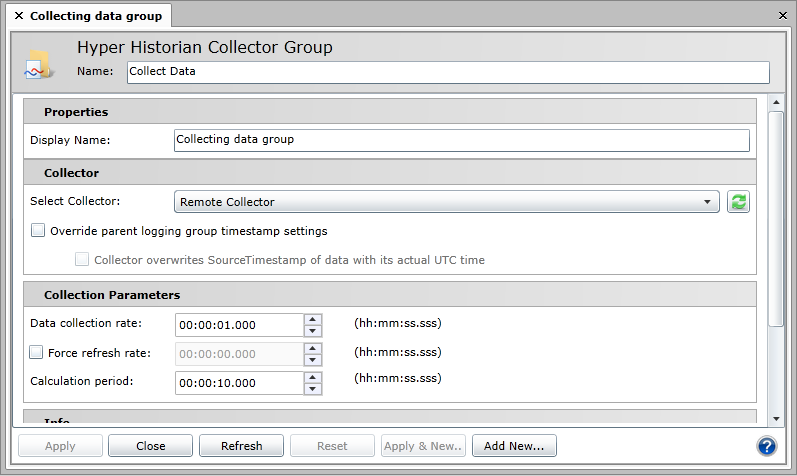
To use the remote collector, you will need to create a collector group that uses it. Once this is done, you can configure the rest like any other collector group.
|
|
Note: This topic uses a pre-configured logging group called Logging Group in the sample Hyper Historian configuration. You can choose whatever logging group you want to use. |
|
|
Note: If you are not familiar with the Collection Parameters settings, please refer to the Data Collectors topic. |
Now that you have a collector group configured (within the Loggers & Groups tree node) to use the remote collector, you can the select the same collector group within the Data Collections tree node to add tags to it like you would for any other collector group. See the topic about Hyper Historian Tags for more details.
You can also view remotely-collected data the same way you would for locally-collected data in the Trend Viewer. The remote collectors load the configuration that is set on the logger machine. The configuration information for the tags that are added to a Collector Group are automatically sent to the appropriate collectors by Hyper Historian when it starts up or when there is a change in the configuration.
Once you are done with your configuration, you can start the Hyper Historian service by clicking the traffic lights in the Home ribbon to turn the, green. If they are already green, refresh the configuration database (by clicking the Refresh button in the Edit section of the Home ribbon) so that the new settings apply. Also, start the Hyper Historian service on the remote collector to start data collection. For more information, refer to the Starting and Stopping Hyper Historian Services topic.
See also:
Collector Groups and Hyper Historian Tags